Cần một phương án dễ dàng và hoàn chỉnh cho văn bản để nói trong giờ việt? thử Responsive
Voice! Tạo một website tương lai chứng minh với ko flash hoặc plugins, không cho từng từ chi phí, văn phiên bản vô hạn nhằm nói!
Văn phiên bản để nói trong giờ đồng hồ việt cần technology tốt để triển khai việc tốt, nhưng công nghệ đó là trở ngại để đi qua, và nó luôn luôn là một nỗi nhức để thực hiện. Responsive
Voice được bạn một vớ cả-trong-một, ngân sách chi tiêu phải chăng và đau-free giải pháp, một trong đó chỉ tất cả trọng lượng 14k
B và giải quyết các vụ việc tổng hợp tiếng nói vô đòi hỏi, trong đó bao hàm (nhưng nuối tiếc là ko giới hạn) cho mỗi nhân vật chi phí, rất cần được khởi tạo bộ động cơ phát biểu sau khoản thời gian tải trang, thời gian chậm trễ giữa các cuộc hotline API, vấn đề tỷ lệ phát biểu, đó là một trong mớ láo độn, công ty chúng tôi đã chọn để sắp tới xếp gọn gàng để chúng ta không phải!
Voice
Khả năng tương thích
Responsive
Voice văn bạn dạng để nói trong tiếng việt được cung ứng nguyên phiên bản trong máy tính xách tay để bàn Chrome, Safari, và i
OS. Chrome trên apk không cung cấp tiếng nói chính của shop chúng tôi trong những hệ điều hành, tuy thế nó không được truy cập vào trình duyệt, do vậy Responsive
Voice rơi trở lại nước ta như ngôi trường hợp tốt nhất có thể có sẵn. Tiếng nói việt nam cũng được sử dụng trong những trình chu đáo không hỗ trợ hữu phiên bản chính của bọn chúng tôi, ví dụ như Internet Explorer, Firefox và Opera.
Bạn đang xem: Chuyển Từ Văn Bản Ra Âm Thanh
Giọng nói chính là nam, cùng được hỗ trợ trong Chrome dành cho máy tính nhằm bàn, OSX Safari, và i
OS Chrome cùng Safari. Đánh giá: 5/10
Giọng nói dự trữ cũng là nam, và được sử dụng trong trình xem xét mặc định của Android, internet Explorer, Firefox và Opera. Đánh giá: 5/10
Hai giọng phái mạnh được tiến hành cho âm nhạc rất giống như nhau, bởi vì đó người tiêu dùng có một trải nghiệm đồng điệu trên cả hai đồ vật được cung cấp và không được hỗ trợ.
Khả năng tiếp cậnHướng dẫn tiếp cận đang ở đây để ở lại, để tạo nên các website và các ứng dụng được giỏi hơn cho toàn bộ mọi người. Từng tiểu bang đã cấu hình thiết lập riêng của bản thân mình hướng dẫn, nhưng so với nội dung trực tuyến gần như là nhà nước đã nắm rõ chi tiết. Số đông các phòng ban lập pháp nói đến các Hướng dẫn tróc nã nhập văn bản Web 2.0 – và đặc biệt là mức AA của mình – là tập hợp lý và phải chăng các hướng dẫn để làm theo, cho đến khi quy định chính thức bao hàm tất cả các nội dung đăng download trên web. Responsive
Voice rất có thể giúp tạo nên trang web của người sử dụng WCAG 2.0, đặc biệt là đối với những người dân đang in vô hiệu hóa hóa, và đều người khổ cực từ một loạt những trở hổ hang đó bao gồm chứng cực nhọc đọc, suy giảm thị lực, cùng tứ chi. Các kinh nghiệm lưu ý web hiện giờ đặt những trở ngại ở vùng trước của họ, phát triển thành không cần thiết khó khăn với bực bội. Những tiêu chuẩn chỉnh WCAG 2.0 sẽ được ra đời để xử lý vấn đề đó, và công ty chúng tôi rất vui lúc được làm 1 phần của bọn chúng tôi.
Với kĩ năng tiếp cận biến chuyển một tiêu chuẩn chỉnh cho xây dựng đáp ứng, chúng tôi đã tạo một giải pháp thị trường vẫn được chứng minh rằng ko chỉ cung ứng văn phiên bản để nói trong giờ việt, nhưng mà còn là một sự đa dạng và phong phú của các ngôn ngữ khác, vào đó xuất hiện các kênh truyền thông media mới và đông đảo nguồn lệch giá tiềm năng cùng với một cái mã!
Responsive
Voice is the solution for your Vietnamese speech synthesis needs, including Vietnamese accent and inflection. Deploy text to speech Vietnamese in your website or application in minutes.
Nhận diện giọng nói là một trong task hơi thú vị. Ngày nay, có không ít API resources tất cả sẵn bên trên thị trường, giúp tín đồ dùng thuận lợi lựa chọn tính năng này hay cái khác ví như Google, Amazon, IBM, Microsoft, Nuance, Rev.ai, mở cửa source Wavenet, open source CMU Sphinx. Trong bài viết này bản thân sẽ trình diễn sơ lược về Google Speech to Text API gốc rễ Nodejs.
Before you begin
Trước khi bước đầu bạn đề nghị set up dự án công trình Google Cloud Platform với Authorization mang lại dự án. Phần này bạn cũng có thể xem chi tiết tại document của Google Speech khổng lồ Text API phần Before you begin
Google Speech to lớn Text API
Trong nội dung bài viết này mình vẫn hướng dẫn các bạn gửi yêu ước nhận dạng giọng nói đến Speech-to-Text bằng phương pháp sử dụng Google Cloud Client Libraries với mình có tác dụng trên gốc rễ Node.js áp dụng thư viện
google-cloud/speech .
Google Speech khổng lồ Text có 3 nhiều loại API requests dựa vào nội dung của audio.
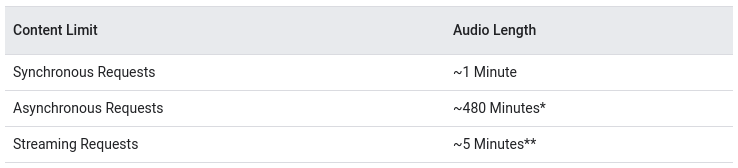
Mình sẽ hướng dẫn thực hiện các requests trên nhằm dịch những loaị audio không giống nhau.
Dịch những audio files bao gồm độ dài ngắn
Phần này trình diễn cách phiên âm một tệp âm nhạc ngắn(dưới 1 phút) thành văn bản bằng cách sử dụng Synchronous Speech Recognition. Đối cùng với audio nhiều năm ta sẽ sử dụng Asynchronous Speech Recognition.
Đầu tiên ta yêu cầu init project:
Tạo folder speech-to-text, chế tạo ra file app.jsDùng npm để thống trị các thư viên npm init
Cài tủ sách google-cloud/speech npm i
google-cloud/speech
Cấu trúc thư mục sẽ sở hữu dạng như hình bên dưới:
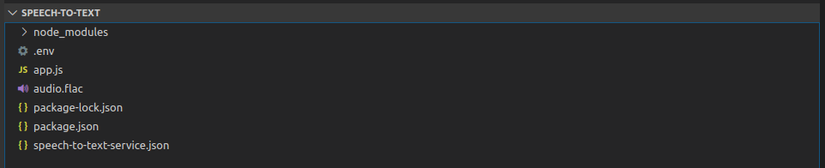
Ở trên đây ta sẵn sàng sẵn một file audio.flac để thực hiện dịch tệp tin này. Để đem lại độ hiệu quả, độ đúng đắn cao hơn cũng tương tự thời gian phản nghịch hồi hợp lí từ thương mại & dịch vụ thì tài liệu này có khuyến nghị về cách cung ứng dữ liệu giọng nói, gần như người tham khảo để vấn đề dịch thanh lịch text tác dụng hơn recommended speech data
speech-to-text-service.json file này đó là private key để xác thực truy vấn vào dịch vụ thương mại mà chúng ta đã tải về ở cách Before you begin. Chú ý nếu chúng ta có đẩy dự án nào có key này lên repository của github hoăc bất kỳ công cụ thống trị source nào khác thì ignore tệp tin này ra ko thì sẽ bị hacker chiếm quyền tài khoản google cloud của bạn.
.env file này chứa phát triển thành GOOGLE_APPLICATION_CREDENTIALS. Biến này còn có giá trị là đường truyền trỏ tới file private key speech-to-text-service.json phía bên trên của bạn, trên bước Before you begin có đề cập tới phần này
Vậy là dứt quá trính setup bây chừ chung ta xem qua đoạn code này vào app.js để thuộc trải nghiệm thương mại dịch vụ này nhé
async function main() // Import dotenv nhằm đọc được biến môi trường trong .env // Nếu chưa có chạy npm i dotenv để thiết đặt nó require("dotenv").config() // Import module fs nhằm đọc tệp tin const fs = require("fs"); // Import tủ sách Google Cloud client const speech = require("
google-cloud/speech"); // Creates a client const client = new speech.Speech
Client(); // Khai báo trỏ tới file local của công ty const filename = "./audio.flac"; // con số kênh gồm trong music của bạn. Còn nếu không đúng đang raise error const audio
Channel
Count = 2; // Khai báo encoding const encoding = "FLAC"; // Tỉ lệ mẫu mã tính bởi Hertz của audio, nêú ko đúng sẽ raise error const sample
Rate
Hertz = 44100; // Khai báo code ngôn từ cần nhấn dạng const language
Code = "en-US"; const config = audio
Channel
Count: audio
Channel
Count, encoding: encoding, sample
Rate
Hertz: sample
Rate
Hertz, language
Code: language
Code, ; const audio = content: fs.read
File
Sync(filename).to
String("base64"), ; const request = config: config, audio: audio, ; // phạt hiện tiếng nói trong audio const
Cuối thuộc thì run node app.js để trải nghiệm dịch vụ này. Khi mình chạy thì hiệu quả sẽ được như bên dưới và còn không ít config để sở hữu được kết quả như mình ước muốn bạn chuyên cần đọc document phê chuẩn của dịch vụ thương mại này nhé Speech-to-Text basics.
Transcription: questions 44 through 46 refer lớn the following conversation
Dịch các audio files bao gồm độ nhiều năm dài
Phần này trình diễn cách phiên âm các tệp âm thanh dài (hơn 1 phút) sang văn phiên bản bằng kỹ năng nhận dạng các giọng nói không đồng bộ.Bạn rất có thể truy xuất hiệu quả của làm việc bằng phương thức google.longrunning.Operations. Công dụng vẫn có sẵn để truy xuất vào 5 ngày (120 giờ).
Xem thêm: Nghị luận xã hội : tuổi trẻ như một cơn mưa rào, dù cảm vẫn muốn ướt thêm
async function main() require("dotenv").config() const speech = require("
google-cloud/speech"); const fs = require("fs"); const client = new speech.Speech
Client(); const filename = "./audio.flac"; const audio
Channel
Count = 2; const encoding = "FLAC"; const sample
Rate
Hertz = 44100; const language
Code = "en-US"; const config = audio
Channel
Count: audio
Channel
Count, encoding: encoding, sample
Rate
Hertz: sample
Rate
Hertz, language
Code: language
Code, ; const audio = content: fs.read
File
Sync(filename).to
String("base64"), ; const request = config: config, audio: audio, ; const
Running
Recognize(request); const
Dịch những âm thanh đầu vào một trong những cách trực tiếp
Dưới đây là một lấy ví dụ về thực hiện nhận dạng các giọng nói phát trực con đường trên luồng music nhận được tự micrô:
Ví dụ này yêu mong bạn thiết lập So
X với nó phải gồm sẵn vào $PATH của bạn. Để setup đối với linux sudo apt-get install sox libsox-fmt-all
require("dotenv").config()// Import node-record-lpcm16 để lưu lại âm thanh// Nếu chưa tồn tại chạy npm install node-record-lpcm16 để mua đặtconst recorder = require("node-record-lpcm16");const speech = require("
google-cloud/speech");const client = new speech.Speech
Client();const encoding = "LINEAR16";const sample
Rate
Hertz = 16000;const language
Code = "en-US";const request = config: encoding: encoding, sample
Rate
Hertz: sample
Rate
Hertz, language
Code: language
Code, , interim
Results: false,;// tạo ra luồng dìm dạngconst recognize
Stream = client .streaming
Recognize(request) .on("error", console.error) .on("data", data => process.stdout.write( data.results<0> && data.results<0>.alternatives<0> ? `Transcription: $data.results<0>.alternatives<0>.transcript
` : "
Reached transcription time limit, press Ctrl+C
" ) );// bắt đầu ghi âm với gửi nguồn vào micrô cho tới API giọng nói.// Đảm bảo So
X được sở hữu đặtrecorder .record( sample
Rate
Hertz: sample
Rate
Hertz, threshold: 0, // những tùy chọn khác, xem https://www.npmjs.com/package/node-record-lpcm16#options verbose: false, record
Program: "rec", silence: "10.0", ) .stream() .on("error", console.error) .pipe(recognize
Stream);console.log("Listening, press Ctrl+C khổng lồ stop.");Xong chúng ta chạy node app.js trên console sẽ xuất hiện dòng Listening, press Ctrl+C khổng lồ stop, bắt đầu bạn thu thanh nó đang dịch trực tiếp đến bạn
Listening, press Ctrl+C to stop.Transcription: hello